여기 에 게시 된 질문과 유사하게 Java로 솔루션을 찾고 있습니다.
즉, 문자열에서 문자 / 문자열의 n 번째 발생 인덱스를 찾는 방법은 무엇입니까?
예 : ” / folder1 / folder2 / folder3 / “. 이 경우 세 번째 슬래시 (/)를 요청하면 folder3 앞에 나타나며이 인덱스 위치를 반환 할 것으로 예상합니다. 내 실제 의도는 문자의 n 번째 발생에서 부분 문자열을 만드는 것입니다.
Java API에서 사용할 수있는 편리하고 즉시 사용할 수있는 방법이 있습니까? 아니면이 문제를 해결하기 위해 자체적으로 작은 논리를 작성해야합니까?
또한,
- Apache Commons Lang의 StringUtils 에서 이러한 목적으로 지원되는 방법이 있는지 빠르게 검색 했지만 찾을 수 없습니다.
- 이와 관련하여 정규 표현식이 도움이 될 수 있습니까?
답변
프로젝트가 이미 Apache Commons에 의존하는 경우를 사용할 수 있습니다 StringUtils.ordinalIndexOf. 그렇지 않은 경우 다음 구현이 있습니다.
public static int ordinalIndexOf(String str, String substr, int n) {
int pos = str.indexOf(substr);
while (--n > 0 && pos != -1)
pos = str.indexOf(substr, pos + 1);
return pos;
}
이 게시물은 여기 에 기사로 다시 작성되었습니다 .
답변
문자열의 N 번째 발생을 찾는 가장 쉬운 해결책 은 Apache Commons에서 StringUtils.ordinalIndexOf () 를 사용하는 것 입니다.
예:
StringUtils.ordinalIndexOf("aabaabaa", "b", 2) == 5답변
두 가지 간단한 옵션이 발생합니다.
charAt()반복 사용indexOf()반복 사용
예를 들면 :
public static int nthIndexOf(String text, char needle, int n)
{
for (int i = 0; i < text.length(); i++)
{
if (text.charAt(i) == needle)
{
n--;
if (n == 0)
{
return i;
}
}
}
return -1;
}indexOf반복적 으로 사용하는 것만 큼 성능이 좋지 않을 수 있지만 올바르게 사용 하는 것이 더 간단 할 수 있습니다.
답변
다음과 같이 시도 할 수 있습니다.
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Main {
public static void main(String[] args) {
System.out.println(from3rd("/folder1/folder2/folder3/"));
}
private static Pattern p = Pattern.compile("(/[^/]*){2}/([^/]*)");
public static String from3rd(String in) {
Matcher m = p.matcher(in);
if (m.matches())
return m.group(2);
else
return null;
}
}정규식에서 몇 가지 가정을 수행했습니다.
- 입력 경로는 절대적입니다 (예 : “/”로 시작).
- 결과에 세 번째 “/”가 필요하지 않습니다.
의견에서 요청한대로 정규식을 설명하려고합니다. (/[^/]*){2}/([^/]*)
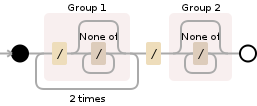
/[^/]*A는/다음[^/]*의 (a하지 않은 문자의 수/)(/[^/]*)이전 표현식을 단일 항목으로 그룹화합니다. 이것은1표현식 의 st 그룹입니다.(/[^/]*){2}그룹이 정확히{2}시간 과 일치해야 함을 의미합니다.[^/]*다시 말하지만/,([^/]*)previos 표현식을 단일 엔티티로 그룹화합니다. 이것은2표현식 의 두 번째 그룹입니다.
이렇게하면 두 번째 그룹과 일치하는 부분 문자열 만 가져 오면됩니다. return m.group(2);
이미지 제공 : Debuggex
답변
aioobe의 답변을 몇 가지 변경하고 nth lastIndexOf 버전을 얻었으며 일부 NPE 문제를 수정했습니다. 아래 코드를 참조하십시오.
public int nthLastIndexOf(String str, char c, int n) {
if (str == null || n < 1)
return -1;
int pos = str.length();
while (n-- > 0 && pos != -1)
pos = str.lastIndexOf(c, pos - 1);
return pos;
}답변
([.^/]*/){2}[^/]*(/)/ 두 번 뒤에 오는 모든 항목을 일치시킨 다음 다시 일치시킵니다. 세 번째는 당신이 원하는 것입니다
매처 / 마지막이고 상태는 말할 수 있습니다
답변
public static int nth(String source, String pattern, int n) {
int i = 0, pos = 0, tpos = 0;
while (i < n) {
pos = source.indexOf(pattern);
if (pos > -1) {
source = source.substring(pos+1);
tpos += pos+1;
i++;
} else {
return -1;
}
}
return tpos - 1;
}